Real World Data Evolved. Data Partnering Infrastructure Hasn’t.
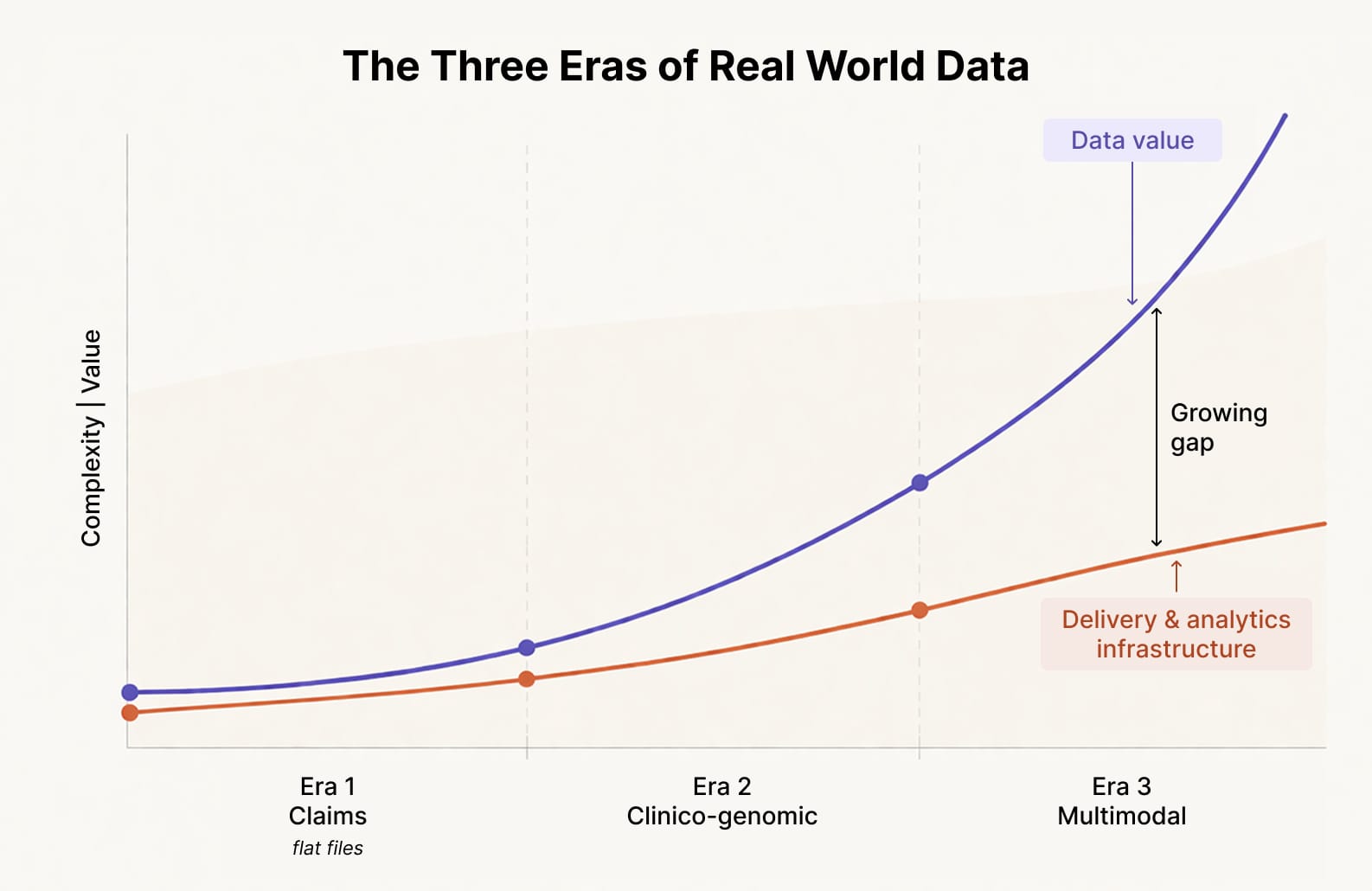

Over the last decade the richness of RWD assets is not the only change, but it’s the economics of how it’s commercialized. Claims datasets that once supported dozens of pharma customers through standardized subscriptions have given way to multimodal assets that command $5M –$50M partnerships but require bespoke effort every time.
We now have a clear gap: data value has scaled exponentially, but delivery infrastructure has scaled linearly. That is the problem, but the good news is that its solvable.
Era One: Claims and the Birth of Scalable Data Licensing
The first generation of RWD commercialization was built on administrative claims for prescription, billing, and insurance data aggregated into large, de-identified datasets.
The model was simple: standardized datasets, delivered as flat files, sold as annual subscriptions. A single dataset could support dozens of pharma customers, with typical contracts in the $500K–$3M range. Delivery was straightforward SFTP transfers of tabular data that could be ingested and queried the same day.
This worked because the data itself was simple. One modality. One structure. One delivery mechanism.
Claims data remains one of the most scalable and widely available sources of real-world evidence. It captures treatment patterns, healthcare utilization, and longitudinal patient journeys across millions of lives. But it describes what was billed, not what actually happened clinically. As precision medicine has matured, the field has needed to layer in richer modalities such as abstracted clinical data, genomics, imaging - that help move from observing care patterns to understanding biological outcomes.
Era Two: Clinico-Genomic Data and the Tradeoff Between Value and Scale
The next wave came from RWD companies that unlocked research-grade data from electronic health records and linked it with genomic profiling. This was a step-function increase in value.
For the first time, pharma teams could analyze real-world outcomes with clinical and molecular granularity, lines of therapy, progression events, biomarker status across defined patient populations. Deal sizes grew accordingly, often reaching $1M–$10M+ per partnership.
But this value came with structural complexity.
Each dataset now depended on multiple parties: health system networks, genomic labs, and data aggregators. Each brought its own governance requirements, data use agreements, and IP considerations. Delivering a “dataset” was no longer a simple extract, but in turn depended on negotiated assembly of permissions.
The operating model changed in a subtle but important way. Deal cycles stretched from weeks to months, delivery became bespoke, and each new customer required incremental effort. What had once been a scalable subscription business began to behave more like a services model. The data became more valuable but the business became less efficient.
Era Three: Multimodal Data and the Breaking Point
Today, we’re in the third era, and the cracks in the flat file model are no longer manageable. The most valuable datasets now combine multiple modalities: clinical abstraction, genomics, imaging - radiology and pathology, claims, SDOH, and even patient-reported outcomes. Leading platforms have built assets with hundreds of thousands of matched patient records and petabytes of associated data.
At this scale, the constraints become physical and architectural. You can’t meaningfully deliver petabyte-scale imaging or sequencing data as a file transfer. You can’t easily de-identify a pathology image the way you de-identify a claims record. You can’t provide a static snapshot of a continuously updating dataset and expect it to remain relevant.
Most importantly, you can’t enforce governance once the data has left your environment. This is where the model breaks.
The Real Constraint: Commercialization, Not Technology
What’s often framed as a technical limitation is, in reality, a business constraint. For a multimodal data producer, every new pharma partnership still triggers the same sequence: define the permissible dataset through a feasibility which in most cases is extensive, build the extract, reconcile governance across partners, format the data for ingestion, and repeat the process for every update.
This does not scale. In most cases, the marginal cost of onboarding a new customer remains roughly constant. The result is a business where revenue can grow, but operational burden grows with it, which then puts pressure on both margins and velocity.
At the same time, governance risk compounds. Once data is delivered externally, enforcement relies entirely on contracts rather than controls. This is a growing concern as datasets incorporate more sensitive and multi-party contributions.
.png)
A Different Model: Bringing the Researcher to the Data
The architectural solution to all of this is conceptually simple, even if the execution is hard: instead of sending data out, you bring the analyst in. This is the core idea behind what the broader industry calls a Trusted Research Environment (TRE) - a secure, controlled computing environment where approved researchers can access and analyze sensitive data without that data ever leaving its source
The principle is straightforward. The data stays where it is. The researcher authenticates into a secure workspace where the data is available. They run their analyses using familiar tools like JupyterLab, RStudio, Python, bioinformatics pipelines or by bringing in their favorite tools - all inside the environment. The data never egresses. Every query, every analysis, every file access is logged in an audit trail.
What This Means for Data Producers
If you’re operating a data business built on clinico-genomic or multimodal assets, the shift from file delivery to governed in-environment access changes your commercial model in ways that compound over time.
First, your pharma partners work with live data, not stale snapshots. If you’re receiving nightly data refreshes from source partners, or continuously ingesting new patient records, that freshness becomes visible to the analysts using your data in its most current form. This alone can change the perceived value of the partnership.
Second, the compliance architecture becomes tractable. Data use agreements can be enforced technically, not just contractually. Access can be scoped at the dataset level, the table level, or the row level depending on what the licensing terms permit. You’re no longer choosing between restricting access broadly (and reducing the data’s utility) or granting access broadly (and accepting governance risk).
Third, the BD cycle compresses. When a prospective pharma partner wants to evaluate your data asset, the first thing they need is a feasibility assessment. E.g., how many patients do you have with this indication, this biomarker profile, this line of therapy? In the flat file world, answering that question requires someone to write a query, run it, and return results. That can days to take weeks depending on the complexity and back and forth with the client. In an environment with self-service cohort exploration or AI-powered data discovery, that feasibility assessment can happen on a live call. The data sells itself.
Fourth, and most importantly, it scales. The environment stays constant while the number of partners accessing it grows. Every additional pharma partner you onboard costs you less marginal effort than the one before. Your infrastructure investment becomes a lever, not a linear cost.
Where AI Fits: Why a TRE Is Necessary But Not Sufficient
A TRE provides the secure foundation with governed access, audit trails, data residency. But a secure environment alone doesn’t change how researchers actually interact with the data. The step change comes from what’s layered on top of it.
This is where Manifold goes beyond the TRE. The platform embeds AI agents directly into the research environment that transform how life sciences researchers and users work with complex multimodal datasets. Researchers can query data in natural language requesting survival curves, exploring mutation frequencies, running cohort comparisons, all without needing to know the underlying schema or write SQL against unfamiliar tables. For translational researchers who are deeply expert in biology but less fluent in data engineering, this removes a barrier that has historically gated time to insight.
Manifold’s AI-powered Cohort Explorer lets pharma partners run feasibility assessments in minutes rather than weeks. A BD team can walk a prospect through the data asset on a live call, filtering by indication, biomarker, and line of therapy in real time. The data demonstrates its own value before a contract is signed.
And the platform doesn’t just serve the data, it brings the computational environment with it. Researchers get access to JupyterLab, RStudio, bioinformatics pipelines, and the ability to bring their own tools, all pre-configured and running inside the governed environment. The result is that a pharma analyst can go from “I want to explore this dataset” to running a publication-ready analysis without ever leaving the platform, and without the data ever leaving the producer’s control.
This is the distinction that matters commercially. A TRE solves the governance problem. Manifold solves the governance and the adoption problem. The data producers who will capture the most value over the next decade aren’t just the ones with the largest or most multimodal datasets. They’re the ones who make those datasets easiest to access, govern, and analyze within a framework that both parties trust.
What This Means Going Forward
One of the most common objections I hear from data producers exploring this shift is about transition cost. The data is already structured a certain way, sitting in existing systems, with existing partner integrations. How disruptive is it to move to a governed-access model?The answer, in our experience at Manifold, is less disruptive than most people expect. The platform connects to your existing cloud storage without requiring data to be moved. Your data stays in the format and location it’s already in. The secure research environment comes to the data rather than the other way around.
The flat file model isn’t going away overnight, and there are partnership contexts where it remains appropriate. But for data producers thinking seriously about scaling their commercial business, the infrastructure to do so already exists. The data you’ve built is the hard part. Getting it where it needs to go, in a way that’s secure, auditable, and scalable, is a solved problem.
