Rewriting the Future of Life Sciences: Our Series B and What Comes Next


Every delay in developing a new medicine is measured in lives. A month lost in analysis is a month that patients wait for therapies that could help them. A year spent navigating technical bottlenecks is a year that families hope for answers that don't come.
The frustrating part is that we've never been more capable. Sequencing costs have collapsed by six orders of magnitude. Gene editing lets us test biological function directly. AI can model protein structures and cellular pathways with remarkable precision. Population-scale datasets—molecular, phenotypic, real-world—are growing exponentially and becoming more accessible. The scientific tools available today surpass anything the field has ever known.
With this foundation, we should be unlocking new diagnostics and therapies at an accelerating pace.
Yet the opposite is happening. Despite unprecedented capability in the lab, the productivity of life sciences has been declining for decades. The number of new FDA approvals per billion dollars spent has halved every nine years since 1950. There's even a name for it in life sciences—Eroom's Law, which is Moore's Law spelled backward. We have more talented people, more advanced methods, and more data than ever before. But the system is producing fewer medicines, not more.
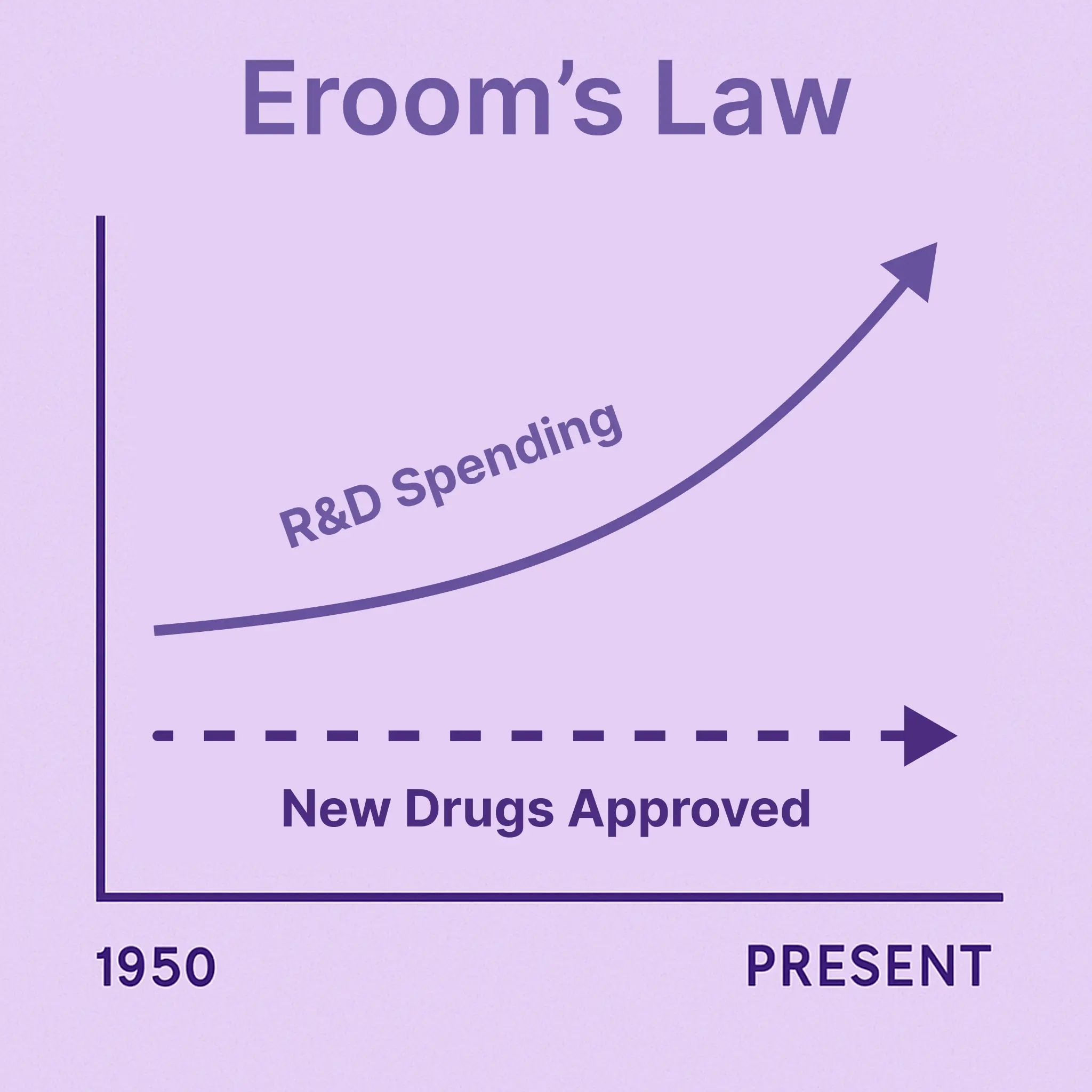
This isn't a scientific problem. The insights are there. The ambition is there. The capability is there.
This is a structural problem.
The Universal Problem: Specialization's Hidden Tax
A key root cause is visible across every knowledge-intensive field: specialization.
As fields advance, they subdivide. Oncology becomes immuno-oncology, targeted therapy, precision diagnostics. Data science becomes bioinformatics, statistical genomics, machine learning engineering. Each subspecialty develops its own language, methods, and systems. This depth is necessary—it's how we push the boundaries of what's possible.
But it creates a bottleneck. There are fewer and fewer people who are “multi-lingual”—who can bridge between the oncologist and the bioinformatician, the clinical team and the data engineers, the scientific question and the technical execution.
This bottleneck has two costs:
- Delay: Work queues up waiting for the experts who can translate across specialties. Questions take weeks to answer because they require coordination across three teams with different vocabularies.
- Errors: When context moves between specialists, it degrades. Assumptions don't carry forward. By the time work comes back, it's not quite what was needed and requires rework.
Everyone feels this in their own work. The meeting to schedule the meeting. The delays waiting for the one person who understands both sides. The "that's not what I meant" moment after work has already been done. This is the tax that specialization imposes on progress.
Why Life Sciences Is Different—And Harder
Life sciences has this problem in the extreme. The data is uniquely complex—molecular, phenotypic, clinical, real-world—each requiring deep domain knowledge to harmonize correctly. The workflows span an unusually broad value chain, from target identification through precision medicine. And critically, the work happens across organizational boundaries: pharma companies working with CROs, academic centers collaborating with industry, multi-site trials coordinating across institutions. The data can't all live in one place for regulatory and competitive reasons.
This creates what we call the Life Sciences Chasm: the gap between expert intent and technical execution. As data volumes grow and modalities multiply, simple questions take months. Organizations with world-class scientists find themselves slowed by operational constraints.

Why Vertical AI Is The Answer
A new category of AI platforms is emerging to solve exactly this class of problem: vertical AI.
These are platforms purpose-built for specific industries—legal services, financial services, customer support—where domain-specific challenges create structural barriers that general-purpose AI cannot overcome. The pattern is consistent: in every major vertical, the winning approach combines advanced AI with deep understanding of the industry's unique data, workflows, and governance requirements.
Vertical AI platforms win because they solve problems that horizontal approaches cannot.
Horizontal platforms lack the specialized architecture for multi-entity collaboration, domain semantics, and regulatory compliance. Point solutions can't span the full value chain. Life sciences needs a platform that goes both deep (understanding the domain) and broad (spanning discovery through precision care), while integrating into existing enterprise architectures.
This is the category Manifold is defining. And it shows up in concrete workflows:
- Multi-entity collaboration on novel real-world datasets holding clinical insight
- Biomarker development for trial enrichment that makes the difference between trial failure and success
- Model validity improvements that matter more than 100x increases in screening
- Market access evidence generation that meets payer demands
Building the Platform: Agent OS + Network Effects
This is why we're building the AI platform for life sciences. It's designed to operate at the intersection of expert intent and technical execution—closing the chasm we've been describing. The Series B funding enables us to accelerate the agentic AI capabilities—what we call the Agent OS—which are a critical part of this platform.
Agent OS provides three core capabilities:
Agents that operate on your data. They understand life sciences data types—molecular, phenotypic, clinical, real-world—and the domain semantics behind them. They harmonize datasets, prepare them for analysis, and work with the schemas and quality requirements your organization already has in place. Crucially, they do this where your data lives, integrating into your existing cloud infrastructure rather than requiring data movement.
Agents that use your tools. They configure Python, R, and specialized analytical workflows so that analyses run correctly and consistently. They understand which methods apply to which questions, how to parameterize them appropriately, and how to interpret results in scientific context.
Agents that reason with your institutional knowledge. They integrate documentation, schemas, models, and organizational context—the accumulated expertise that lives in your systems and your teams. This allows them to interpret questions intelligently, choose appropriate methods, and produce results that reflect the science behind them.
Together, these capabilities make your organization's expertise accessible at the point of work. Domain experts no longer need to translate questions into technical specifications or wait for specialized capacity. They can explore hypotheses directly, iterate quickly, and maintain ownership of their workflows without becoming software engineers. The result is a shift in how expert attention is allocated: less time navigating systems, more time advancing the work that matters.
The data flywheel. As more teams use the platform, establishing collaborations becomes easier and constructing novel datasets becomes easier. Teams can enable data access, share analyses, reuse workflows, and build on each other's work without coordination overhead. The flywheel of progress speeds up.
Our Series B
Today I'm excited to share that Manifold has raised $18 million in our Series B, led by Reach Capital, with participation from SilverArc Capital, Industry Ventures, and our existing investors TQ Ventures and Calibrate Ventures. This brings our total capital raised to $40 million.
This investment enables us to accelerate the work already underway across three areas:
Expanding the Agent OS. We're advancing how agents operate on multimodal biomedical data, use scientific tools, and leverage institutional context to accelerate work—from biomarker discovery and model validation through trial design and real-world evidence generation. The goal is to make complex analyses faster, more accessible, and more reliable across the full life sciences value chain.
Deepening collaboration infrastructure. We're extending features that enable teams to share analyses, reuse context, and work across organizational boundaries with appropriate governance and data sovereignty. This is critical for a field where most important work happens across organizations, not within them.
Scaling the data ecosystem. We're deepening our work with customers and partners to compound value for the entire ecosystem. As more organizations join the platform, the workflows become richer, the collaboration becomes easier, and the data flywheel accelerates.
Over the past year, we've achieved momentum that validates this approach. We've deployed Manifold to support diverse workflows. This momentum is compounding. And this funding positions us to accelerate it.
The Future We're Building
We're at an inflection point in life sciences. The tools have never been more powerful. The data has never been richer. And now, AI can finally close the gap between expert intent and execution.
The future we're building is one where life sciences organizations move at the speed their expertise deserves. Where asking a critical question and getting an answer happens in minutes, not months. Where collaboration across organizations is seamless and governed. Where the expertise that exists in teams and data becomes accessible at the point of work.
This is why vertical AI platforms are winning in every major industry—they solve problems that general-purpose tools cannot. Life sciences is next. And we're building the platform that will define this category.
The path forward is acceleration. Every improvement in time to insight unlocks new possibilities. Every month we compress is a month closer to getting medicines to the people who need them. A parent. A partner. A child. A friend.
Thank you to our customers, partners, team, and Series B investors. Your belief in this mission shapes the work ahead of us.
Let's close the chasm and build the future of life sciences together.
